|
AI är i grunden statistik, men inte enkel deskriptiv statistik — utan specifikt modellbaserad statistisk prediktion baserad på indata. Denna process kallas inferens. AI träning, däremot, består av algoritmer som hittar de optimala parametrarna för modellen genom att minimera prediktionsfel utifrån träningsdata. Kvaliteten på AI beror därför både på vilken modell som används, vilket mått för prediktionsfel som tillämpas, och på kvaliteten hos träningsdatan.
Det som gör AI-träning så beräkningsmässigt krävande är att numeriska metoder måste optimera ett mycket stort antal parametrar (tiotusentals till miljarder) för att minimera prediktionsfelen. Utvecklingen av praktiskt användbara AI-applikationer har därför blivit möjlig tack vare den snabba utvecklingen av datorhårdvara.
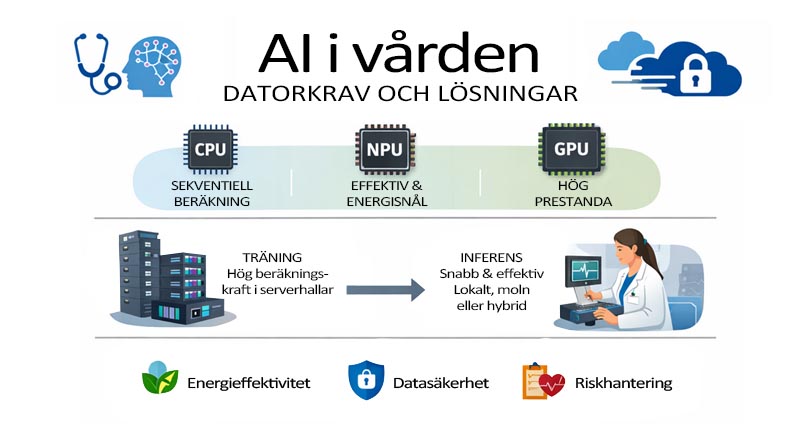
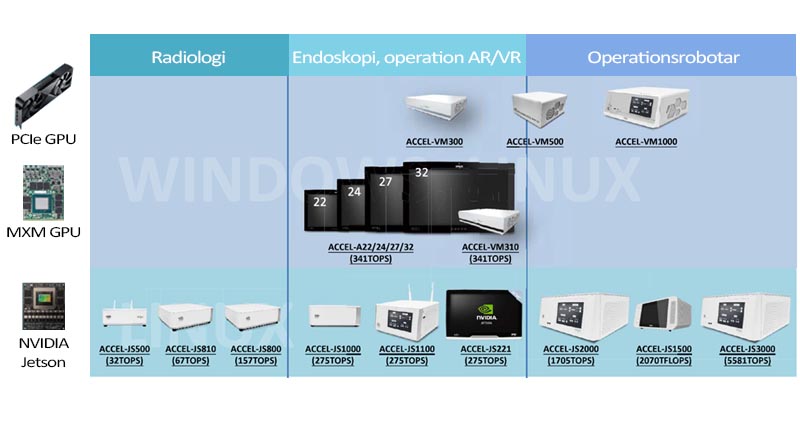
AI kan användas för att stödja diagnostik, optimera behandlingar och assistera vid journalföring. För hög precision och realtidsanalys i vårdmiljön krävs effektiva algoritmer, vältränade modeller, ändamålsenlig hårdvara och lämpliga API-lager. Våra EN60601-1 klassade datorer finns i modeller med det hårdvarustöd som krävs för allt från lokal inferens till hybridlösningar mellan edge och moln, med balans mellan prestanda, energieffektivitet och datasäkerhet.
CPU, GPU och NPU
• CPU (”vanlig” processor): Flexibel och kraftfull för komplexa men sekventiella beräkningar. Parallellkapaciteten är begränsad av antal kärnor och hypertrådar, vilket gör CPU bäst för preprocessing, styrlogik och enklare AI-modeller. Passar för molnbaserad inferens eller lokal inferens av mycket små modeller.
• NPU (Neural Processing Unit): Effektiv för lokal inferens av små kvantiserade modeller. Hög TOPS/Watt gör den energieffektiv. Exempel: Intel Core Ultra (gen 15) har integrerad NPU för AI-acceleration.
• GPU (Graphics Processing Unit): Kraftfull för lokal inferens av medelstora till stora modeller med hög precision. NVIDIA GPU:er använder CUDA och Tensor Cores, finns som diskreta kort (t.ex. RTX 6000 Ada) eller integrerade SoC-lösningar som Ampere-GPU i Orin IGX/AGX. GPU:er har hundratals till tiotusentals CUDA-kärnor och tiotals till hundratals Tensor Cores, optimerade för massiv parallellism. Både CUDA och Tensor Cores är viktiga för AI-modeller, medan sekventiella operationer hanteras mer effektivt av CPU.
AI-modeller har olika minnes- och prestandakrav för att kunna köras med rimlig svarstid. Riktigt stora modeller (tex ChatGPT, DeepSeek) körs därför på servrar eller i molnet, eftersom minneskapacitet, bandbredd och latens i vanliga PC begränsar möjligheten att köra dem lokalt. Minnesbehovet beror på antalet parametrar och vilken numerisk precision som används. Kvantiserade modeller är samma modell men med lägre parameterprecision, vilket gör det möjligt att köra dem med mindre minne och lägre energiförbrukning, ofta vid lokal inferens. |